Od publikování prvního algoritmu Tomáše Mikolova, převádějícího slova na vektory se zajímavými vlastnostmi (psal jsem o něm zde), uběhlo již několik let. Stále se však lidé snaží více či méně uspokojivě vysvětlit, jak je možné, že "kings – king + queen = queens". Před časem napsal podobný text na svém blogu Piotr Migdal. Článek je inspirativní, ale obsahuje řadu nepodložených tvrzení a předpokladů. Rád bych zde prezentoval alternativní zdůvodnění vycházející ze stejných myšlenek, které však bude preciznější.
Jedním z hlavním přínosů většiny takzvaných word embedding algoritmů (cbow, skipgram, glove, atd.) je schopnost projektovat lexikální jednotky (nejčastěji slova) do vektorového prostoru, ve kterém morfologické, syntaktické i některé sémantické vlastnosti těchto slov zachovávají lineární závislosti. Znamená to, že když například vektor slova king odečteme od vektoru slova kings, dostaneme vektor, který lze významově chápat jako vektor přechodu od singuláru k plurálu. Pokud tento vektor přičteme k libovolnému substantivu v singuláru, dostaneme se v daném vektorovém prostoru velmi blízko k vektoru stejného slova v plurálu. Tuto vlastnost ilustruje známý obrázek převzatý z původního článku T. Mikolova.
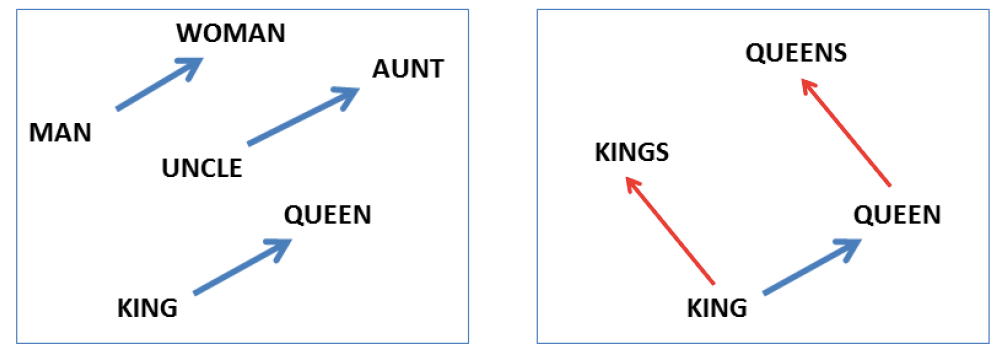
Obrázek 1: Vektorová reprezentace slov. Zdroj: T. Mikolovov et al. : Linguistic Regularities in Continuous Space Word Representations, NAACL 2013.
Tohoto fenoménu lze využít k hledání slovních analogií. Mohli bychom se ptát na slovo W, pro které platí: king se má ke kings jako queen k W. V obecnosti bychom chtěli ukázat, že pokud se slovo a má ke slovu A stejně jako slovo b ke slovu B, potom přibližně platí va – vA = vb – vB, kde vx je vektor reprezentující slovo x, získaný některým z algoritmů word2vec (viz Obr. 1).
Word2vec je zobecňující pojmenování pro metody převodu slova na jeho vektorovou reprezentaci. Pro účely tohoto textu se zaměřme konkrétně na nejznámější algoritmus Skip-gram s negativním samplováním.
Abychom mohli dané tvrzení dokázat, je třeba se nejdříve vypořádat s vágní definicí vztahu “mít se stejně k”. To většina literatury zanedbává a spokojuje se jen s intuicí. Pro větší přehlednost budeme v následujícím textu tučnou kurzívou označovat lexikální jednotky, kurzívou jejich vlastnosti a tučně zápis lexikální jednotky v korpusu.
Vyjděme z Firthova pohledu na lexikální význam. Jeho známý citát „You shall know a word by the company it keeps“ lze, volně přeloženo, chápat tak, že význam slova je dán slovy, která se s ním často pojí. Podle jeho tvrzení tedy platí, že dvě slova mají podobný význam tehdy, když se v textech často vyskytují ve stejných kontextech. Jedná se o v praxi často využívaný pohled na lexikální sémantiku.
Význam slova a lze ve Firthově pojetí formalizovat jako soubor pravděpodobností SEM(a) = 〈P(w | a): w ∈ L〉, které vyjadřují pravděpodobnost výskytu slova w blízko slova a v jazyce L. Ten nechť je reprezentovaný dostatečné velkým jazykovým korpusem. Blízkost je určena nějakou maximální vzdáleností v textu (měřeno počtem slov, která je oddělují).
Dalším důležitým poznatkem je Fregeho princip kompozicionality, který nám říká, že význam složitějšího lexikálního výrazu je dán významem dílčích jednotek a způsobem jejich kombinace. Tento princip se dá vztáhnout i na význam slov – slovo je nositelem souboru dílčích významů, která dohromady dávají význam celého slova. Například slovo queen lze zjednodušeně chápat jako anglické substantivum označující osobu, která má současně vlastnosti být panovníkem s královským titulem a být ženského pohlaví.
Vycházejíce z předchozích dvou formulací můžeme tedy význam slova queen definovat pomocí pravděpodobností〈P(wi | je panovník ∧ je ženského pohlaví )〉, v obecnosti jako 〈P(wi | a1, a2, … an)〉.
Nyní již lze zadefinovat slovní analogie: a se má k A stejně jako b k B tehdy, když existují vlastnosti a1... an, b1... bn, c a d takové, že
SEM(a) =〈P(wi | a1, a2, … an, c)〉
SEM(A) =〈P(wi | a1, a2, … an, d)〉
SEM(b) =〈P(wi | b1, b2, … bm, c)〉
SEM(B) =〈P(wi | b1, b2, … bm, d)〉.
Pokud budou platit následující statistické nezávislosti výskytů vlastností slov v korpusu
P(a1, a2, … an) ⊥ P(c)
P(a1, a2, … an) ⊥ P(d)
P(b1, b2, … bm) ⊥ P(c)
P(b1, b2, … bm) ⊥ P(d)
Dostaneme pro všechna wi
}{P(\mathbf{w_i} | \mathbf{A})} = \dfrac{P(\mathbf{w_i} | \mathbf{b})}{P(\mathbf{w_i} | \mathbf{B})}")
neboť
}{P(\mathbf{w_i} | \mathbf{A})} = \dfrac{P(\mathbf{w_i} | a_1 \dots a_n, c)}{P(\mathbf{w_i} | a_1 \dots a_n, d)} = \dfrac{P(\mathbf{w_i}, a_1 \dots a_n, c)P(a_1 \dots a_n, d)}{P(\mathbf{w_i}, a_1 \dots a_n, d)P(a_1 \dots a_n, c)} =")
P(\mathbf{w_i})P(a_1 \dots a_n)P(d)}{P(a_1 \dots a_n, d | \mathbf{w_i})P(\mathbf{w_i})P(a_1 \dots a_n)P(c)} = \dfrac{P(a_1 \dots a_n | \mathbf{w_i})P( c | \mathbf{w_i})P(d)}{P(a_1 \dots a_n | \mathbf{w_i})P( d | \mathbf{w_i})P(c)} =")
P(d)}{P( d | \mathbf{w_i})P(c)} = \dfrac{P(\mathbf{w_i}|P(b_1 \dots b_m, c)}{P(\mathbf{w_i}|P(b_1 \dots b_m, d)} = \dfrac{P(\mathbf{w_i} | \mathbf{b})}{P(\mathbf{w_i} | \mathbf{B})}")
Nyní již lze analogie snadno zdůvodnit
}{P(\mathbf{w_i} | \mathbf{A})} = \dfrac{P(\mathbf{w_i} | \mathbf{b})}{P(\mathbf{w_i} | \mathbf{B})}")
}{P(\mathbf{w_i})} \cdot \dfrac{P(\mathbf{w_i})}{P(\mathbf{w_i} | \mathbf{A})} \Bigg) = \mbox{log} \Bigg( \dfrac{P(\mathbf{w_i} | \mathbf{b})}{P(\mathbf{w_i})} \cdot \dfrac{P(\mathbf{w_i})}{P(\mathbf{w_i} | \mathbf{B})} \Bigg)")
}{P(\mathbf{w_i})}-\mbox{log} \dfrac{P(\mathbf{w_i} | \mathbf{A})}{P(\mathbf{w_i})}=\mbox{log} \dfrac{P(\mathbf{w_i} | \mathbf{b})}{P(\mathbf{w_i})}-\mbox{log} \dfrac{P(\mathbf{w_i} | \mathbf{B})}{P(\mathbf{w_i})}")
Přičemž z definice pointwise mutual information platí
 -\mbox{PMI}(\mathbf{w_i},\mathbf{A}) =\mbox{PMI}(\mathbf{w_i},\mathbf{b}) -\mbox{PMI}(\mathbf{w_i},\mathbf{B})")
Teď využijeme výsledek práce Levy & Yoav Goldberg, 2014, kde bylo ukázáno, že algoritmus Skip-gram s negativním samplováním aproximuje rozklad matice slov a kontextů, kde jednotlivé buňky matice odpovídají (až na konstatní posuv) pointwise mutual information. Autoři Arora & kol., 2015 sice ukazují, že aproximace se blíží skutečnosti jen u vektorů vysoké dimenze a navrhují vlastní důkaz, pro potřeby tohoto článku nám však tvrzení stačí:
 \approx v_\mathbf{w} \cdot v_\mathbf{a}")
Odsud již dostaneme kýženou lineární závislost vektorů, odpovídající slovním analogiím:

Problémem důkazu je předpoklad nezávislosti výskytu jevů v korpusu, který samozřejmě ve většině případů neplatí. To je něco, čím se žádný ze mně známých důkazů analogií v algoritmech word2vec kvůli vágní nebo chybějící definici významu slov nezabýval. Je možné, že existuje silnější důkaz, který předpoklad nezávislosti jevů nepotřebuje. Druhou možností je, že slovní analogie fungují přesně jen v případě statisticky nezávislých jevů. Ani pro jedno však nemám zdůvodnění, a proto nechávám otázku otevřenou pro případné zájemce z řad čtenářů.
Pro tuto chvíli však nechme stranou exaktní důkazy a podívejme na několik příkladů analogií napočítaných algoritmem skip-gram na korpusu českého internetu.
| + slovo | - slovo | + slovo | nejbližší slovo výsledku | kosinová podobnost |
|---|---|---|---|---|
| královna | král | řidič | řidička | 0.785 |
| Řidička | 0.682 | |||
| cyklistka | 0.625 | |||
| rybářka | rybář | ošetřovatel | ošetřovatelka | 0.692 |
| Ošetřovatelka | 0.619 | |||
| canisterapeutka | 0.605 | |||
| královna | kozel | řidič | řidička | 0.609 |
| čtyřiadvacetiletá | 0.532 | |||
| dvaadvacetiletá | 0.511 | |||
| rybářka | kozel | ošetřovatel | krotitelka | 0.574 |
| ošetřovatelka | 0.547 | |||
| pasačka | 0.541 |
V tabulce jsou vždy uvedena tři slova, která slouží jako dotaz a ke každému dotazu 3 nejbližší slova nalezená v prostoru spolu s kosinovou podobností. U prvního příkladu, kde je dotazem v(královna) – v(král) + v(řidič) vidíme, že analogie krásně fungují a dvě nejbližší nalezená slova jsou řidička a Řidička. Ve druhém příkladu byla záměrně použita slova, pro která předpoklad nezávislosti výrazněji neplatí. Vlastnost být rybářem a být muž, spolu jistě pozitivně korelují. Podobně jako vlastnosti být ošetřovatel a být žena. Přestože kosinová podobnost nejbližšího kandidáta je nižší než v předchozím případě, stále je výsledkem správná odpověď ošetřovatelka. Třetí příklad je extrémnější. Dotazem je zde v(královna) – v(kozel) + v(řidič) a výsledkem stále řidička, i když už s výrazně nižší kosinovou podobností. Tento výsledek je trochu zarážející a neodpovídá naší intuici. Zdá se, že vlastnost být mužem a být ženou je natolik dominantní, že převáží všechny ostatní. Teprve poslední příklad, který kombinuje extrémy předchozích ukázek, dopadne jinak. Na dotaz v(rybářka) – v(kozel) + v(ošetřovatel) najdeme jako nejbližší slovo krotitelka.
Těchto pár příkladů samozřejmě vůbec nic nedokazuje. Je z nich však vidět, že hledání analogií pomocí word2vec přístupů je velmi odolné vůči šumu. Může tedy dobře fungovat i v případě, že by byl pro přesný důkaz požadavek nezávislosti jevů nutný. Navíc nepřesností, které do procesu hledání analogií vstupují, je mnoho (velikost a zaměření korpusu, velikost reprezentujících vektorů, apod.) a je jen otázkou, jak velkou chybu jednotlivě způsobují. Velká odolnost vůči nim je podle mého názoru zajištěna velkou řídkostí vektorového prostoru, ve kterém analogie hledáme. Pro dotaz v(královna) – v(kozel) + v(řidič) najdeme jako odpověď slovo řidička jednoduše proto, že se v blízkosti žádné jiné slovo nenachází.