Když psal Tomáš Mikolov svoji disertační práci, jistě netušil, jaký rozruch její důsledky v celosvětové NLP komunitě vyvolají. Práce se zabývala jazykovými modely postavenými na neuronových sítích. Jazykové modely, které se běžně využívají při strojovém zpracování řeči nebo automatickém překladu, jsou matematické modely, umožňující predikovat slova následující po nějaké posloupnosti slov tak, aby vzniklý text co nejlépe zapadal do daného jazyka. Pokud tedy např. máme posloupnost slov „Šel do lesa na“, je v češtině mnohem pravděpodobnější, že bude následovat „houby“ nebo „dřevo“ než „mikroskop“ nebo „vítr“. Neuronová síť tedy řeší relativně jednoduchou úlohu strojového učení s učitelem, kde jako trénovací data slouží velký korpus textů. Mikolov si však všiml, že synaptické váhy neuronové sítě mezi vstupem a skrytou vrstvou sítě představují vektorovou reprezentaci slov v n-rozměrném prostoru, mající velmi zajímavé vlastnosti.
Prvním důležitým rysem je, že slova, která jsou si významově podobná, leží v daném prostoru blízko sebe a naopak slova nepodobná mají od sebe daleko. Mnohem zajímavější je ale vlastnost, kterou Mikolov nazývá „linguistic regularity“. Rozumí se tím zejména to, že velkou část sémantických i morfologických vlastností slov je možné reprezentovat unikátním vektorem. Pokud tento vektor přičteme k vektoru libovolného slova, posuneme se k těsné blízkosti vektoru slova, které se od původního liší právě touto vlastností (pokud takové slovo existuje). Jednoduchá ilustrace ve dvourozměrném prostoru je znázorněna na obrázku 1 vlevo.
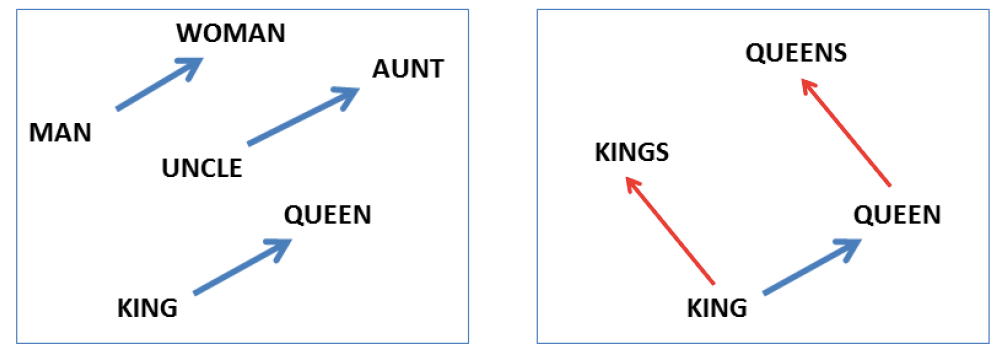
Obrázek 1: Vektorová reprezentace slov. Zdroj: T. Mikolovov et al. : Linguistic Regularities in Continuous Space Word Representations, NAACL 2013.
Modré šipky zde představují vektory, reprezentující vlastnost změny pohlaví z mužského na ženské. Z obrázku je vidět, že se vždy jedná o vektor stejného směru a velikosti. Lze ho tedy jednoduše spočítat odečtením vektorové reprezentace libovolné dvojice slov, reprezentujících objekty lišící se pouze pohlavím. Označme vektorovou reprezentaci slova s jako vec(s). Vektor změny mužského pohlaví na ženské potom získáme například jako vec("woman") – vec("man") nebo vec("queen") – vec("king"). Vektor změny ženského pohlaví na mužské bude mít stejnou velikost jen opačný směr.
Takovéto vektorové operace se samozřejmě dají kombinovat, viz obrázek 1 vpravo. Ten se dá interpretovat jako odpověď na dotaz „King“ se má ke „kings“ jako se má „queen“ k? Správnou odpovědí je samozřejmě „queens“. Získáme ji tak, že zahledáme slovo, jehož vektorová reprezentace má nejblíže vektoru vec(„kings“) – vec(„king“) + vec(„queen“). Vhodnou metrikou vzdálenosti vektorů je například kosinová vzdálenost. Pokud máme dostatečně velký a reprezentativní trénovací korpus, můžeme se ptát i na relativně složité dotazy, jako Kdo je prezidentem Mexika? Příkladem vektorových operací, které by vedly k výsledku může být vec(„Obama“) – vec(„USA“) + vec(„Mexico“).
Zpracování velkých korpusů pomocí původního algoritmu však bylo výpočetně příliš náročné. Proto vznikly dva zjednodušené modely, pomocí kterých je možné vygenerovat slovní vektory podobných vlastností mnohem efektivněji – CBOW a Skip-gram. CBOW model je jednoduchá dopředná neuronová síť, která predikuje slovo v korpusu na základě sousedních slov. Model Skip-gram naopak predikuje okolní slova ze slova, které leží mezi nimi. Odkazy na různé implementace těchto dvou modelů lze najít na domovské stránce projektu word2vec: https://code.google.com/p/word2vec/.
Po velkém úspěchu těchto modelů vznikla řada dalších přístupů, jejichž cílem bylo také nalezení vektorové reprezentace slov podobných vlastností. Nejvýraznějším z nich je zřejmě stanfordský model GloVe. Žádný z těchto modelů však kvalitativně výrazně word2vec nepřevyšuje, takže nemá smysl se jimi v tomto článku zabývat.
Zájemci si můžou vyzkoušet on-line word2vec model napočítaný nad anglickou wikipedií například na adrese http://deeplearner.fz-qqq.net.